Download the Source Code from The Page of Downloads
Cellection sort is a variant of cellection framework, a cellular automata based problem solving framework. Cellular Automata are finite deterministic machines that can model highly complex physical phenomenon. The principles of locality and uniformity give these automata an edge over the conventional computational mechanisms, which is very hard to perceive unless we actually use them in our daily computations. However, there are hardly any problems in our computational field (compared to physical phenomenon) that can fully utilize the power of cellular automata. Hence building a cellular framework for solving computational functions is nothing but reducing the dose of cellular automata. However, here we dare to make this step - not with the interest of solving the computational problems in cellular automated way - but rather with the intention of demonstrating the power, at least partially, of cellular automata.
Cellection Sort is the result of the application of Cellection Framework for sorting problems. Cellection framework is a way of programming the programmable matter. Just the way one solves complex functions with the mechanisms of structured programming methods, cellection framework provides mechanisms for solving the problems using programmable matter methods. What distinguishes the programmable matter is the availability of a massive amount of fine-grained parallelism [1].
Cellection Sort, then, is the result of the application of programmable matter methods for sorting problems. What distinguishes this from other sorting mechanisms is the presence of data-independence along with the more important property - learning. This and all other adaptations of Cellection Framework in general, use data-independent operations in their workings, and can "by heart" the computed results with the ability to recall and use them at any later point with full precision.
In the following, we examine a way of solving the sorting problem using data-independent operations. By data-independent we mean, the path of execution remains the same irrespective of the nature of the data the algorithm is working upon. The importance of data-independence need not be stressed twice, considering the fact that even the best algorithms turn out to be worst performers with mismatched data. Quick sort is one of the best examples - while it proves to be optimal on average, it performs worst for inversely sorted data (if not taken enough care in pivot selection). This is true for all data-dependent algorithms - they perform well only when they are presented with the data having the properties they are expecting. Any slight variation in the nature of data leads to large variations in the path of execution.
This property of data-sensitivity poses a critical restriction on the applicability of algorithms. While we have many algorithms for solving the problem of sorting, not all of them are independent of data-sensitivity and so cannot be used as general purpose sorters. No matter how many times we have answered it before, we always encounter the problem once more- which algorithm should I use to sort this data?
Cellection sort, just like cellection framework, operates on the relations among the data rather than the data itself. It accepts a relation table as input and produces an indexed list as output. For a problem of sorting n-elements, the relation table would be a two-dimensional array of size n x n, with the produced output list being a single dimensional array of size n.
A cell [i,j] in the input table indicates the relation between ith and jth data elements, and could be written as relation( i, j ); It should be noted that the table need not be symmetric. That is, relation( i, j ) need not be equal to relation( j, i ). Typically the values of these relations would be {=,>,<,#}. Since the input data elements are treated as numbers (in case of strings, the individual characters can be treated as equivalent ASCII-numbers), the relation between any two data elements should be from one of these four mentioned relations. In fact, the relation set {=,>,<} should suffice. However, we use the fourth relation {#} to indicate the don't care condition, the significance of which would be made clear as we progress further.
Equipped with these four relations, we now could turn any data-dependent sorting algorithm into data-independent one. In the following, we use the odd-even transportation sorting as the basis to prove this. In fact, any other sorting algorithm can also be used as the base to achieve the corresponding data-independent algorithm in similar fashion. Here our purpose in choosing the odd-even transportation sorting is - it is easier to demonstrate and suits best for explanation.
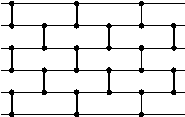
Figure1: Odd-even transportation sorting network (n=6)
The conventional odd-even transportation sort works in phases. In even phases, elements at even positions compare their values with their next neighbors and exchange with them if necessary. In odd phases, elements at odd positions would take up the onus of comparing their values with their next neighbors and exchanging with them if appropriate. A total of n phases would require to sort the data of n elements. Figure1 presents an example with n=6. The algorithm for this conventional method would look like below.
void Odd-EvenTransportationSort(int nArray[], int nCount)
{
for(int i = 0; i < nCount; i++)
for(int j = i%2; j < nCount-1; j+=2)
if(nArray[j] > nArray[j+1])
Swap(nArray+j, nArray+j+1);
}
As per this above code snippet, it is clear that the algorithm directly operates on the input data elements supplied in nArray[]. Depending on even phase or odd phase, determined by checking if i is even or odd, the elements nArray[j] and nArray[j+1] are compared and exchanged as necessary. Controlled by i, this process is carried out as many times as the number of elements in the array, given by nCount.
The modifications that we make to this conventional method are as follows. First we create a pool of relation tables and corresponding sorted results for a reasonable value of n, and would use that pool of pre-computed values as the basis for new computations. Towards this extent we also avoid operating directly on the input data elements. Instead we build a corresponding relation table for the given data elements and use it to index into the pre-computed pool of relation table - sorted result pairs. Typically the values obtained from such indexing would once again need to be de-indexed into data elements before they could be actually used afterwards. The process of pre-computation is as follows.
For a data consisting of n elements, the relation table generated would be of size n x n. Now, recall that each cell in the table represents a relation between the actual data elements and so can take any of the four values {=,>,<,#}. With two bits to represent the four relations {00 =,01 >,10 <,11 #} a table with n x n cells requires a storage of 22 x n x n units. However, we could reduce this by understanding that the lower part of the table (including the main diagonal) can be ignored without loosing any information. The remaining upper part then would be of size n x (n-1)/2; which requires a storage of 2n x (n-1) units. For example, when n=4, the size of the relation table would be n x n = 16, while the size of the upper triangle would be 4 x 3 / 2 = 6; This means, the table of 16 cells (requiring 232 units) can be equivalently represented with just 6 cells (requiring 212 units) without loosing any information. The following presents a relation table for some pseudo data elements { 56, 23, 45, 11, 78 }. Observe that the grayed region could be discarded without loosing any information.
|
|
56 |
23 |
45 |
11 |
78 |
|
56 |
00 = |
01 > |
01 > |
01 > |
10 < |
|
23 |
10 < |
00 = |
10 < |
01 > |
10 < |
|
45 |
10 < |
01 > |
00 = |
01 > |
10 < |
|
11 |
10 < |
10 < |
10 < |
00 = |
10 < |
|
78 |
01 > |
01 > |
01 > |
01 > |
00 = |
Thus, for a data with n elements we can have utmost 2n x (n-1)/2 different relation tables. Each relation table would lead to one sorted result. Typically the sorted result would be a list of indices pointing to the actual data elements in the sorted order. For example, the above table would produce a sorted result = {3,1,2,0,4}, which when de-indexed gives us {11,23,45,56,78}; Note that we have used 0-based indexing for the sorted result. Being purely based on the indices, these sorted results are independent of the actual data elements they are sorting, and hence can be used to evaluate the sorted output of any n data elements satisfying the underlying relation (i.e.. they should produce the same relation table).
Consider a pre-computation involving n=4 data elements. Among the 16 cells of the n x n relation table, we just need the upper 6 cells. By varying the relation in each cell we could get different sorted result. In total we can have utmost 26 sorted results. We could actually find these sorted results by taking any hypothetical 4-element data and applying any existing sorting algorithm such as insertion or selection sort. These sorted results would look like,
........
SortedResult[=,=,=,=,=,=] = {0,1,2,3};
SortedResult[>,>,>,<,>,>] = {3,1,2,0};
SortedResult[>,>,<,>,<,<] = {2,1,0,3};
........
By representing each relational operator with two bits, as mentioned before, the above would look like the following.
........
SortedResult[000000000000] = {0,1,2,3};
SortedResult[010101100101] = {3,1,2,0};
SortedResult[010110 011010] = {2,1,0,3};
........
Now, with these results in place, given any 4-element data we could give the instantaneous sorted order for them just with a single lookup into this SortedResult[] array. For example, for data = {28,13,22,-8} the sorted result could be produced instantaneously by using the lookup SortedResult[010101100101] = {3,1,2,0}; which when de-indexed gives us {-8,13,22,28}, which is the required output (Note that, the data in question produces 010101100101 in its relation table, which we have used as the index into the SortedResult[] array). Similarly any 4-element data can be sorted instantaneously with single array lookup.
Reason behind choosing 4-data elements for pre-computation is - memory limitation. With 4 elements the
SortedResult[] need to hold 212 listed indices, with each list composed of 4 indices, this amounts to 4096 x 4 x 2 = 32768 bits. With n=5 this would become 220 x 5 x 3 bits. As we increase the n value further the storage requirements would go beyond obvious limits. For most practical purposes, n=4 should suffice. However, when the size of data elements is less than 4, we could use dummy values to make it up 4. For these dummy values, none of the three relations {=,>,<} are valid. We need to use the fourth relation {#}, the don't care relation for them. In such cases these don't care dummy values would not be treated for sorting, and hence would be passed onto output as they are, without changing their positions. This facilitates us in discarding the dummy values easily when we need to extract the actual data from the produced output. On the other hand, when we need to sort more than 4-elements, we could achieve that by sorting 4-elements at a time and merging the results. The Odd-even transportation sort when modified to bring this effect would look like the following (with n =8).
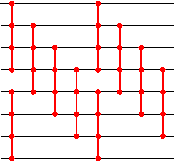
Figure2: Modified Odd-even transportation sorting network (n=8)
With all the modifications described till now in place, the algorithm for the cellection sort looks like the following:
void CellectionSort(int nArray[], int nCount, SortedResult Results[]) { int nSortedOutput[4],nSortedResultIndex; for(int i=0; i<ncount; i++) for(int j=i%4; j<nCount-3; j+=4) { nSortedResultIndex = RelationTable(nArray[j],nArray[j+1],nArray[j+2],nArray[j+3]); nSortedOutput[0] = nArray[j+Results[nSortedResultIndex].Index[0]]; nSortedOutput[1] = nArray[j+Results[nSortedResultIndex].Index[1]]; nSortedOutput[2] = nArray[j+Results[nSortedResultIndex].Index[2]]; nSortedOutput[3] = nArray[j+Results[nSortedResultIndex].Index[3]]; nArray[j] = nSortedOutput[0]; nArray[j+1] = nSortedOutput[1]; nArray[j+2] = nSortedOutput[2]; nArray[j+3] = nSortedOutput[3]; } }From the above code it is clear that the algorithm depends highly on the relation table in its computations. It uses the relation table entries as the index into the pre-computed SortedResult[] array. A block of 4 elements are sorted in unit time. To Sort n elements in this method we require O(n2) time. However, on hardware implementations this could be completed with in O( n ) time.
The advantages that one gain in using this method are:
- The first and foremost advantage is that this would allow a common framework for all sorting problems to operate upon and so maintenance is easy. Typically the phrase "common framework for all sorting problems" means, the cellection sort is independent of any data that it operates on and is independent of any method that it relies on. The algorithm can sort in both ascending and descending orders without changing even a single line of code. Loading the pre-computed results from external files makes this possible. Supplied with ascending sorted results makes it sort in ascending order and supplying a descending sorted results makes it sort in descending order.
- At the cost of memory, any computation need be carried out only once for the first time. Any repeated requests for the same or similar computation can be served instantaneously. One question that one might find unanswered is - how is this different from "caching"?. Sometimes referred to as dynamic programming, the method of caching also stores the computed results in memory and serves any later requests for the same computation instantaneously. The difference is - "caching (dynamic programming)" can serve only "same" requests, they cannot serve "similar" requests. This can be understood clearly from the following table.
The table presents a series of computing request for both methods. The caching method, it is clear from the above, fails to identify the "similarity" in the requests and computes them afresh. This is what exactly the problem with data-dependency is. Cellection framework removes the data-dependency from its operations by relying upon the relations among data. It has got all the strengths of "caching" but none of its weaknesses. In other words, Cellection sort does the same thing as caching but does it in a better way, the data-independent way. But then it makes a difference of whole world.
Caching
Cellection Sort
Comments
Request 1
Sort(10,25,8,12)
Compute
Compute
-
Request 2
Sort(10,25,8,12)
Lookup
Lookup
Same as Request 1
Request 3
Sort(-8,13,-4,1)
Compute
Lookup
Similar to Request1
Request 4
Sort(11,26,9,13)
Compute
Lookup
Similar to Request1
Request 5
Sort(10,25,8,12)
Lookup
Lookup
Same as Request 1
- With enough storage at our disposal, there would be no limit to the amount of computations to "learn by heart". For example, a low end machine can be dedicated to solely "learn" the computations, while a high end machine can just utilize those results as and when required. Using number of machines in parallel is also another viable option. For example, we could use one machine to learn sorting all 5-element data, while another machine in parallel learns to sort 6 or 7-element data. However, one point worth noting is, learning to sort 6-element data from 5-element data is much effective way than to learn from scratch.
- We could, in course of time, establish new relations among the problems themselves by studying the relations among the data that they operate on. After all, two algorithms operating on same data relations could only differ in their paths of execution. A unified framework that captures these relations among the paths of executions could open the doors to an entirely new world of computation.
Tommaso Toffoli, Programmable Matter Methods, http://pm1.bu.edu/~tt/publ/pmm.pdf , Future Generation Computer Systems, June 98.
By
P.GopalaKrishna